Диагностика сайта и Страницы в поиске. Разбор ошибок в Яндекс.Вебмастер
Опубликовано: 23.08.2018
 – Александр Смирнов")
Доброго дня, читатели блога SEO-Дилетанта . Я всегда получаю много вопросов от вебмастеров, владельцев сайтов и блогеров об ошибках и сообщениях, которые появляются в Яндекс.Вебмастер. Многих такие сообщения пугают.

Но, хочу сказать, не все сообщения бывают критичны для сайта. И в ближайших статьях я постараюсь максимально полно охватить все возможные вопросы, которые могут возникать у вебмастеров. В данной статье пойдет речь о разделах:
[Вебинар]: Поиск эффективных страниц сайта
Диагностика — Диагностика сайта Индексирование — Страницы в поиске О том, что такое Яндекс.Вебмастр и зачем он нужен, я писала ещё несколько назад. Если вы не знакомы с данным инструментом, ознакомьтесь сначала со статьей по ссылке.
Поисковая оптимизация сайта. Азы диагностики сайта
Диагностика сайта
Возможные проблемы
1. В файле robots.txt не задана директива Host
Данное замечание Яндекс примечательно тем, что директива Host не является стандартизированной директивой, ее поддерживает только поисковая система Яндекс. Нужна она в том случае, если Яндекс неправильно определяет зеркало сайта.
Как правило, зеркало сайта определяется Яндексом автоматически на основе URL, которые формирует сама CMS, и на основе внешних ссылок, которые ведут на сайт. Чтобы указать главное зеркало сайта, не обязательно указывать это в файле robots.txt. Основной способ — использовать 301 редирект, который либо настроен автоматически в CMS, либо необходимый код вносится в файл .htachess.
Обращаю внимание, что указывать директиву в файле robots.txt нужно в тех случаях, когда Яндекс неправильно определяет главное зеркало сайта, и вы не можете повлиять на это никаким другим способом.
CMS, с которыми мне приходилось работать в последнее время, WordPress, Joomla, ModX, по умолчанию редиректят адрес с www на без, если в настройках системы указан адрес сайта без приставки. Уверена, все современные CMS обладают такой возможностью. Даже любимый мной Blogger правильно редиректит адрес блога, расположенного на собственном домене.
2. Отсутствуют мета-теги
Проблема не критичная, пугаться ее не нужно, но, если есть возможность, то лучше ее исправить, чем не обращать внимание. Если в вашей CMS по умолчанию не предусмотрено создание мета-тегов, то начните искать плагин, дополнение, расширение или как это называется в вашей CMS, чтобы иметь возможность вручную задавать описание страницы, либо, чтобы описание формировалось автоматически из первых слов статьи.
3. Нет используемых роботом файлов Sitemap
Конечно, лучше эту ошибку исправить. Но обратите внимание, что проблема может возникать и в тех случаях, когда файл sitemap.xml есть, так и в тех, когда его действительно нет. Если файл у вас есть, но Яндекс его не видит, просто перейдите в раздел Индексирование — Файлы Sitemap. И вручную добавьте файл в Яндекс.Вебмастер. Если такого файла у вас вообще нет, то в зависимости от используемой CMS, ищите варианты решения.
Файл sitemap.xml находится по адресу http://vash-domen.ru/sitemap.xml
4. Не найден файл robots.txt
Все же этот файл должен быть, и если у вас есть возможность его подключить, лучше это сделать. И обратите внимание на пункт с директивой Host.
Файл robots.txt находится по адресу http://vash-domen.ru/robots.txt
На этом фонтан ошибок на вкладке Диагностика сайта у меня иссяк.
Вкладку Безопасность и нарушения я пропускаю. К счастью, на нескольких десятках сайтов у меня ни разу не было сообщений в этом разделе. Поделиться нечем.
Индексирование
Страницы в поиске
Начнем именно с этого пункта. Так будет легче структурировать информацию.
Выделяем в фильтре «Все страницы»
 Опускаемся ниже, справа на странице «Скачать таблицу» Выбираем XLS и открываем файл в Excel.
Опускаемся ниже, справа на странице «Скачать таблицу» Выбираем XLS и открываем файл в Excel.
 Получаем список страниц, которые находятся в поиске, т.е. Яндекс о них знает, ранжирует, показывает пользователям.
Смотрим, сколько записей в таблице. У меня получилось 289 страниц.
Получаем список страниц, которые находятся в поиске, т.е. Яндекс о них знает, ранжирует, показывает пользователям.
Смотрим, сколько записей в таблице. У меня получилось 289 страниц.
А как понять, сколько должно быть? Каждый сайт уникален и только вы можете знать, сколько страниц вы опубликовали. Я покажу на примере своего блога на WordPress.
В блоге на момент написания статьи имеется: Записи — 228 Страницы — 17 Рубрики — 4 Метки — 41 + главная страница сайтаВ сумме имеем 290 страниц, которые должны быть в индексе. В сравнении с данными таблицы разница всего в 1 страницу. Смело можно считать это очень хорошим показателем. Но и радоваться рано. Бывает так, что математически все совпадает, а начинаешь анализировать, появляются нестыковки.
Есть два пути, чтобы найти ту одну страницу, которой нет в поиске. Рассмотрим оба.
Способ первый. В той же таблице, которую я скачала, я разделила поиск на несколько этапов. Сначала отобрала страницы Рубрик. У меня всего 4 рубрики. Для оптимизации работы пользуйтесь текстовыми фильтрами в Excel.
 Затем Метки, исключила из поиска Страницы, в результате в таблице остались одни статьи. И тут, сколько бы статей не было, придется просмотреть каждую, чтобы найти ту, которой нет в индексе.
Затем Метки, исключила из поиска Страницы, в результате в таблице остались одни статьи. И тут, сколько бы статей не было, придется просмотреть каждую, чтобы найти ту, которой нет в индексе.
Опять же, если на примере WordPress, обратите внимание, какие разделы сайта у вас индексируются, а какие закрыты. Здесь могут быть и страницы Архива по месяцам и годам, страницы Автора, пейджинг страниц. У меня все эти разделы закрыты настройками мета тега robots. У вас может быть иначе, поэтому считайте все, что у вас не запрещено для индексации.
Если взять для примера Blogger, то владельцам блогов нужно считать только опубликованные Сообщения, Страницы и главную. Все остальные страницы архивов и тегов закрыты для индексации настройками.
Способ второй. Возвращаемся в Вебмастер, в фильтре выбираем «Исключенные страницы».
 Теперь мы получили список страниц, которые исключены из поиска. Список может быть большой, намного больше, чем со страницами, включенными в поиск. Не нужно бояться, что что-то не так с сайтом.
Теперь мы получили список страниц, которые исключены из поиска. Список может быть большой, намного больше, чем со страницами, включенными в поиск. Не нужно бояться, что что-то не так с сайтом.
При написании статьи я пыталась работать в интерфейсе Вебмастера, но не получила желаемого функционала, возможно, это временное явление. Поэтому, как и в предыдущем варианте, буду работать с табличными данными, скачать таблицу можно также внизу страницы.
Опять же, на примере своего блога на WordPress я рассмотрю типичные причины исключения.
В полученной таблице нам в первую очередь важна колонка D — «httpCode». Кто не знает, что такое ответы сервера, прочитайте в википедии . Так вам будет легче понять дальнейший материал.
Начнем с кода 200. Если вы можете попасть на какую-то страницу в интернете без авторизации, то такая страница будет со статусом 200. Все такие страницы могут быть исключены из поиска по следующим причинам:
Запрещены мета тегом robots Запрещены к индексации в файле robots.txt Являются неканоническими, установлен мета тег canonicalВы, как владелец сайта, должны знать, какие страницы какие настройки имеют. Поэтому разобраться в списке исключенных страниц должно быть не сложно.
Настраиваем фильтры, выбираем в колонке D — 200

Теперь нас интересует колонка E — «status», сортируем.
Статус BAD_QUALITY — Недостаточно качественная. Самый неприятный из всех статус. Давайте разберем его.
У меня в таблице оказалось всего 8 URL со статусом Недостаточно качественная. Я их пронумеровала в правой колонке.

URL 1, 5, 7 — Страницы фида, 2,3,4,5,8 — служебные страницы в директории сайта wp-json. Все эти страницы не являются HTML документами и в принципе не должны быть в этом списке.
Недостаточно качественной может являться только HTML страница с информацией для пользователя. Здесь же на лицо программная ошибка, которую, не нужно бояться.
Поэтому внимательно просмотрите свой список страниц и выделите только HTML страницы.
Статус META_NO_INDEX. Из индекса исключены страницы пейджинга, страница автора, из-за настроек мета тега robots
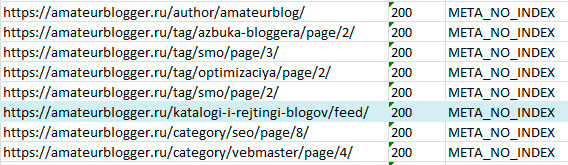
Но есть в этом списке страница, которой не должно быть. Я выделила url голубым цветом.
Статус NOT_CANONICAL. Название говорит само за себя. Неканоническая страница. На любую страницу сайта можно установить мета тег canonical, в котором указать канонический URL.
 Это очень полезная настройка, когда CMS создает много дублей одной страницы, когда на сайте много страниц пейджинга.
Это очень полезная настройка, когда CMS создает много дублей одной страницы, когда на сайте много страниц пейджинга.
На этом пока заканчиваю. Остальные разделы будут подробно разобраны в следующих постах блога. Подписывайтесь на обновления блога.
Если у вас в Вебмастере есть ошибки из описанных в этой статье разделов, которые я не разобрала, пишите в комментариях, будем разбираться вместе.